



In the early days the processing used to take a lot of time, days, in fact, to process or even implement the machine learning algorithms, but with the introduction of tools such as Hadoop, Azure, KNIME, and other big data processing software’s the text mining has gained enormous popularity in the market.
We define textual analysis to be the automated analysis of unstructured textual data, containing within it the methodologies of text mining and text analytics. Leading textual analysis use cases include Sentiment Analysis, Natural Language Processing (NLP), Information Extraction, and Document Categorization. Historically, text analytics practitioners have backgrounds in computational linguistics and knowledge management, whereas text mining practitioners come from the fields of data mining and statistics.
Differences between Text Mining and Text Analytics:
• Text Mining and Text Analytics solve the same problems, but use different techniques and are complementary ways to automatically extract meaning from text.
• Text Analytics is developed within the field of computational linguistics. It has the ability to encode human understanding into a series of linguistic rules which are generated by humans are high in precision, but they do not automatically adapt and are usually fragile when tried in new situations.
• Text mining is a newer discipline arising out of the fields of statistics, data mining, and machine learning. Its strength is the ability to inductively create models from collections of historical data. Because statistical models are learned from training data they are adaptive and can identify “unknown unknowns”, leading to the better recall. Still, they can be prone to missing something that would seem obvious to a human.
• Text analytics and text mining approaches have essentially equivalent performance. Text analytics requires an expert linguist to produce complex rule sets, whereas text mining requires the analyst to hand-label cases with outcomes or classes to create training data.
• Due to their different perspectives and strengths, combining text analytics with text mining often leads to better performance than either approach alone.
Key Points
• Text mining and text analytics can each be used be to solve any text analysis problem – Choosing the right approach (or mix) depends on whether the problem is well-defined or open-ended, whether there are historical labeled data available or well-established lists of keywords, and the cost of false positive and false negative errors. For rapidly changing domains, statistical approaches are able to identify weaker patterns that are predictive, whereas updating linguistic rules can be very labor intensive. These characteristics lead to a natural precision/recall trade-offs. Statistical approaches have better recall “out of the box”, but linguistic rules have higher precision. The best solutions find the right balance given the specific business problem.
• Improving text analytics with text mining – For text analytics projects, there are a number of ways to incorporate statistical text mining to improve the results. Most pure text analytics practitioners view text mining as a method for exploring the corpus and suggesting possible rules. For example, statistical approaches can quickly identify words with similar meanings and/or usage, identify important keywords, and suggest possible multi-word phrases. This additional information can help guide the creation of new linguistic rules.
• Beyond suggesting new rules, text mining can replace or augment existing linguistic rules. One of the strengths of a statistical approach is the ability to combine evidence from multiple features. As the rule-sets increase in size, complexity, and the number of special cases, text mining can reduce the rule maintenance burden and increase the ability to uncover new and surprising knowledge from the corpus.
• Improving text mining with text analytics – Text mining uses statistical approaches to combine multiple features into a single decision. The best way to improve text mining is to upgrade the quality of the features through traditional text analytics approaches such as lexicons, taxonomies, and rules. These help to ensure that feature creation follows “common sense”, including not breaking multi-word phrases, creating domain-specific linguistic rules, and accounting for technical language.
• Driven by continued growth in online applications such as targeted advertising, statistical approaches for textual analysis is one of the fastest growing areas of machine learning – The truly “big” data associated with most online tasks amplifies the need for the rapid scalability provided by a statistical approach. Look for the rapid expansion of statistical text mining that began with Google in the late 1990s to continue for the foreseeable future.
List of options that describe the comparisons between Text mining and Text Analytics:
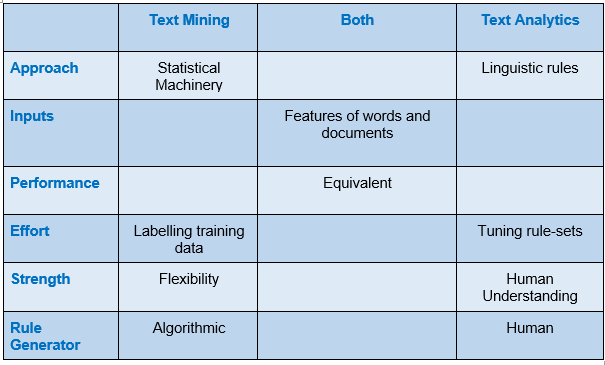
Table 1: Text Mining and Text Analytics
Linguistic and statistical approaches for processing text provide complementary results for extracting value from unstructured textual data. Though each has been practiced independently, the most effective solutions combine their strengths. This balances the precision of linguistically based text analytics with the powerful recall of a statistical text mining approach. The rapid growth of “big data” and predictive analytics means that the best techniques for achieving this balance will be constantly evolving, yet the tools exist today to make great progress on the wide variety of textual analytics challenges.













.svg)






interesting blog thank you.
Thank you
This blog was super helpful and on point, thank you so much. I'm reading all the other blogs as well. Thanks.
Thank you