
Data Science Training In Bangalore With Placement Support
In association with :

Certificate from prestigious IITM Pravartak

Students Enrolled
15,213

Reviews
4.8

Duration
6 Months
Immersive IITM Learning Experience
15+ Hours of Immersive Training at IITM Research Park campus for 2 days.
Interactive sessions by professors of IITM.
An industry-leading IITM Pravartak Certificate.
Internationally Valued Certification Credentials


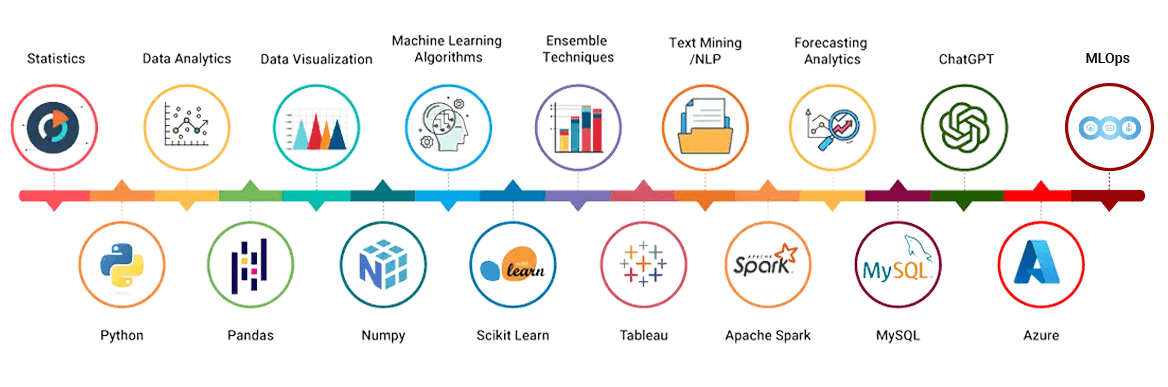
Master 15+ Industry-Leading Tools & Technologies
Data Science Certification from IITM Pravartak:
Accelerate your career with Data Science certification from IITM Pravartak , one of the leading universities in Germany. This course is a perfect blend of theory, case studies and capstone projects. The course curriculum has been designed by IITM Pravartak and considered to be the best in the industry. Get noticed by recruiters across the globe with the international certification. Post certification one will gain the alumnus status in IITM Pravartak.
What is the certification process?
Post completion of the training, one should take an online examination facilitated by the university and should attain 60% or more to complete the course and gain the certification. Subsequently participants can check their alumnus status on IITM Pravartak.
Advanced Certification Program in Data Science and AI for Digital Transformation from IITM Pravartak:
ExcelR, in association with IITM, brings to you an add-on certification for your Data Science Course.
This certification program provides you with:
- 15+ Hours of Interactive Live-Virtual Sessions by professors of IITM.
- Optional 2-day Campus Immersion in the beautiful, state-of-the-art IITM.
- A prestigious IITM Pravartak Certificate.
What is the certification process?
During the period of your course, interactive live-virtual sessions will be conducted by professors of IITM. An optional campus immersion will also be planned, whereby a slot will be created, and you will travel to Chennai for a two-day experience at the IITM campus. Post training, you will take a short quiz on the topics discussed in the session, which will unlock your Advanced Certification in Data Science and AI for Digital Transformation from IITM Pravartak.
Data Science Course Training
ExcelR offers Data Science course, the most comprehensive Data Science course in the market, covering the complete Data Science lifecycle concepts from Data Collection, Data Extraction, Data Cleansing, Data Exploration, Data Transformation, Feature Engineering, Data Integration, Data Mining, building Prediction models, Data Visualization and deploying the solution to the customer. Skills and tools ranging from Statistical Analysis, Text Mining, Regression Modelling, Hypothesis Testing, Predictive Analytics, Machine Learning, Deep Learning, Neural Networks, Natural Language Processing, Predictive Modelling, R Studio, Tableau, Spark, Hadoop, programming languages like R programming, Python are covered extensively as part of this Data Science training. ExcelR is considered as the best Data Science training institute which offers services from training to placement as part of the Data Science training program with over 400+ participants placed in various multinational companies including E&Y, Panasonic, Accenture, VMWare, Infosys, etc. ExcelR imparts the best Data Science training and considered to be the best in the industry.
Why Should You Choose ExcelR For Data Science Training?
If you are serious about a career pertaining to Data science, then you are at the right place. ExcelR is considered to be one of the best Data Science training institutes. We have built careers of thousands of Data Science professionals in various MNCs in India and abroad. “Training to Job Placement” – is our niche. We do the necessary hand-holding until you are placed. Our expert trainers will help you with upskilling the concepts, to complete the assignments and live projects.
ExcelR has a dedicated placement cell and has partnered with 150+ corporates which will facilitate the interviews and help the participants in getting placed. ExcelR is the training delivery partner in the space of Data Science for 5 universities and 40+ premier educational institutions like IIM, BITS Pilani, Woxen School of Business, University of Malaysia, etc. Faculty is our strength. All of our trainers are working as Data Scientists with over 15+ years of professional experience. Majority of our trainers are alumni of IIT, ISB and IIM and a few of them are PhD professionals. Owing to our faculty, ExcelR’s certification is considered to be the best Data Science certification offered in this space. ExcelR offers a blended learning model where participants can avail themselves classroom, instructor-led online sessions and e-learning (recorded sessions) with a single enrollment. A combination of these three modes of learning will produce a synergistic impact on learning. One can attend an unlimited number of instructor-led online sessions from different trainers for 1 year at no additional cost. No wonder ExcelR is regarded as the best Data Science training institute to master Data Science concepts and crack a job.
What Is Data Science? Who Is Data Scientist?
Data Science is all about mining hidden insights of data pertaining to trends, behaviour, interpretation and inferences to enable informed decisions to support the business. The professionals who perform these activities are said to be a Data Scientist / Science professional. Data Science is the most high-in-demand profession and as per Harvard and the most sort after profession in the world.
Why One Should Take The Data Science Course?
Is Data Science certification being worth pursuing as a career?
The answer is a big YES for myriad reasons. Digitalization across the domains is creating tons of data and the demand for the Data Science professionals who can evaluate and extract meaningful insights is increasing and creating millions of jobs in the space of Data Science. There is a huge void between the demand and supply and thereby creating ample job opportunities and salaries. Data Scientists are considered to be the highest in the job market. Data Scientist career path is long-lasting and rewarding as the data generation is increasing by leaps and bounds and the need for the Data Science professionals will increase perpetually.
- 1.4 Lakh jobs are vacant in Data Science, Artificial Intelligence and Big Data roles according to NASSCOM
- The world will notice a deficit of 2.3 Lakh Data Science professionals by 2021
- The Demand for Data Scientist professionals has increased by 417% in the year 2018, in India, as per the Talent Supply Index
- Data Science is the best job to pursue according to Glassdoor 2018 rankings
- Harvard Business Review stated that ‘Data Scientist is the sexiest job of the 21st century’
You May Question If Data Science Certification Is Worth It?
The answer is yes. Data Science / Analytics creating myriad jobs in all the domains across the globe. Business organizations realised the value of analysing the historical data in order to make informed decisions and improve their business. Digitalization in all the walks of the business is helping them to generate the data and enabling the analysis of the data. This is helping to create myriad data science/analytics job opportunities in this space. The void between the demand and supply for the Data Scientists is huge and hence the salaries pertaining to Data Science are sky high and considered to be the best in the industry. Data Scientist career path is long and lucrative as the generation of online data is perpetual and growing in the future.
Why ExcelR Is The Best Data Science Training Institute?
ExcelR offers the best Data Science certification online training along with classroom and self-paced e-learning certification courses. The complete Data Science course details can be found in our course agenda on this page.
Who Should Do The Data Science Course?
Professionals who can consider Data Science course as a next logical move to enhance in their careers include:
- Professional from any domain who has logical, mathematical and analytical skills
- Professionals working on Business intelligence, Data Warehousing and reporting tools
- Statisticians, Economists, Mathematicians
- Software programmers
- Business analysts
- Six Sigma consultants
- Fresher from any stream with good Analytical and logical skills
Interview Preparation Sessions
Participants who have completed the Data Science course training and the projects will be put under our Placement Incubation Program. As part of this program, participants will undergo a thorough interview preparation process on Data Science. A huge repository of Data Science Interview questions with answers will be provided for the participants to prepare. A dedicated Data Science Subject Matter Expert (SME) will help in resume building, conduct mock interviews and evaluate each participant's knowledge, expertise and provide feedback. Our SMEs will do the necessary handholding on interview preparation process till the time the participant is placed. Guidance is also provided on Linkedin profile building and tricks of the trade to improve the marketability of the resume. - ExcelR Management
Projects
"Daily" Twitter Data Analysis for a Product
As more and more people are expressing their views and opinions on various microblogging websites about various products and services. There has been a surge of data generated by the users, these websites have people sharing their thoughts daily.
Sentiment Analysis with the help of Natural Language Processing technique for identifying the sentiments of a product or service
Natural Language Processing
Customers are looking for more information before buying a product on E-commerce websites. Amazon introduced a new feature 'question and answer' search field for products.
The project is to build an information retrieval system from Amazon products data based on NLP techniques. Top 5 relevant answers to be retrieved based on input question
Predicting Loan defaulters
Reducing the risk of fraudulent loans by carefully evaluating the risk & at the same time increasing profits by rejecting only those loans, which have the potential of defaulting
Warranty Cost prediction
The objective of the analysis to predict an item when sold, what is the probability that customer would file for warranty and to understand important factors associated with them
Predict flight delays
Predict which flights would be delayed and by how long?
Flight delays cost the industry an estimated $25 billion every year More than 60 percent of frequent flyers cite delays among the things about air travel that they find most dismaying. And the costs are spread around - an extra $25 in parking here, a missed business meeting there. Carriers, meanwhile, pay an estimated $62 per minute in crew, fuel, maintenance and other costs. It adds up.
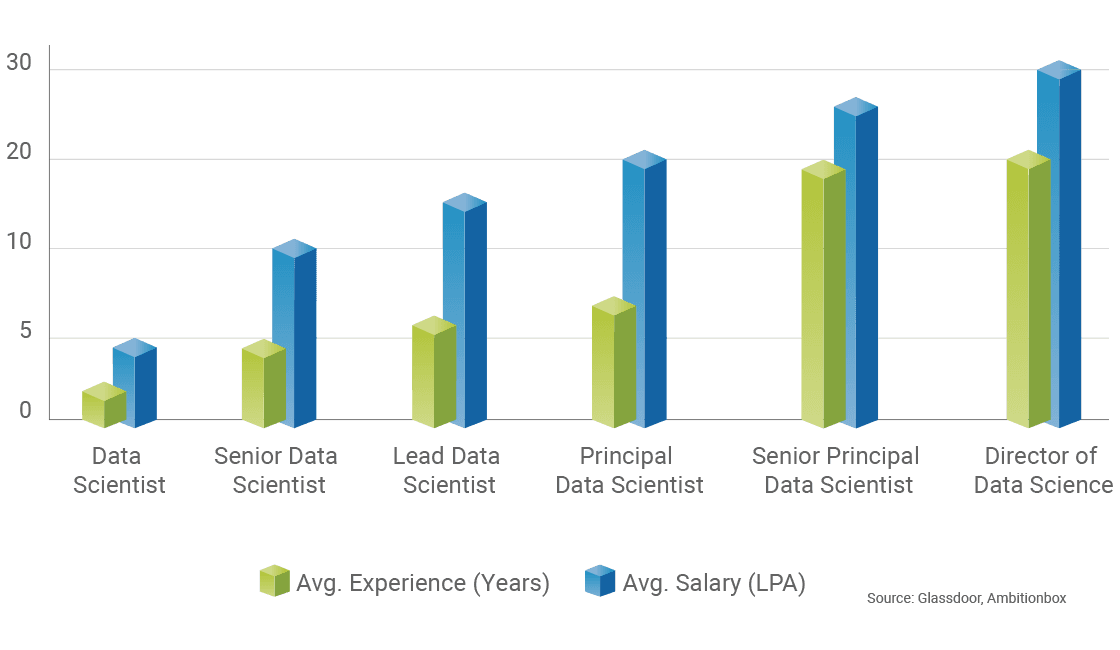
Career Progression and Salary Trends
Learning Path
Contact Our Team of Experts
Why ExcelR?
Participants Placed Through ExcelR

Githin James

Anushri Agarwal

Apoorva

Avimanyu Basu

Bharat Kumar

Faraz

Gopal

Manasa
.jpg&w=384&q=75)
Manohar

Nalini Khade

Yogesh

Rajeswar Rao

Vikram Arora

Vishal Dixit
Sushant

Swetha
Dinesh

Vasantha
Amit MG
Agarwal Subham
Murali

Nikhil
Teja

Saurabh Chawla
Prayash
Mihir
Shirin

Sayantan
Santhosh
Anup Harne
Nitin Mishra

Chetan Reddy Velma

Santosh Kumar Isukapalli

Tarakeshwari Junge

Naveen Reddy
Pavan
Rajashekar
Byl Lavanya
Saif

Nagaraj
Nagireddy
Venu
Raj
Sai Krishna

Neha

Swostiman

Hari
Pradeep
Sneha
Praveen
Bhagya Lakshmi
Saipriya

Midhun
2.jpg&w=384&q=75)
Madhavi
2.jpg&w=384&q=75)
Tanya
2.jpg&w=384&q=75)
Rohan
Bhavana Tangirala
1.jpg&w=384&q=75)
Alisha Kar
1.jpg&w=384&q=75)
Ruhi Ragini

Gopal
1.jpg&w=384&q=75)
Pragya

Rajan
Testimonials


FAQs
What Is JUMBO PASS?
- The all new and exclusive JUMBO PASS is the latest initiative taken by ExcelR to offer you access to attend unlimited batches over the duration of 365 days. You will be able to attend unlimited number of classes for the course of your choice.
What Are The Prerequisites For This Data Science Training?
- As such, there is no prerequisite for undertaking this training. However, it is highly desirable if you possess the following skills sets
- Mathematical and Analytical expertise
- Good critical thinking and problem-solving skills
- Technical knowledge of Python, R and SAS tools
- Communication skills
What Are The Career Opportunities For Data Science Professionals?
- Data Science has become the spine around which crucial company decisions are made. Organizations are paying top dollars to recruit Business Analytics professionals and the demand is only going to increase with the influx of data from new sources. The career roles that you can cherry pick are
- Data Analyst
- Research Analyst
- Data Scientist
- Data Analyst
- Big Data Analytics Specialist
- Business Analyst Consultant / Manager
What Kind Of Salary Can I Expect As A Data Science Professional?
- Just as the saying goes - You reap what you sow, your experience plays an important factor in determining the package that you will be offered
- Entry Level - Up to 5 Lakhs
- Intermediate Level - Up to 8 Lakhs
- Experienced Level - Up to 12.5 Lakhs
- Advanced Level - Up to 18 Lakhs
- Expert Level - More than 25 Lakhs
What Is Instructor-Led Online Training?
- Instructor-led online training is an interactive mode of training where participants and trainer will log in at the same time and live sessions will be done virtually. These sessions will provide scope for active interaction between you and the trainer.
How Many Batches Can I Attend, If Enrolled For Training?
- ExcelR offers a blended model of learning. In this model participants, can attend classroom, instructor-led live online and e-learning (recorded sessions) with a single enrolment. A combination of these 3 will produce a synergistic impact on the learning. One can attend multiple Instructor-led live online sessions for one year from different trainers at no additional cost with the all new and exclusive JUMBO PASS.
Is This A Live Training Or Recorded Sessions?
- The training is a live instructor-led interactive session done at a specific time where participants and trainer will log in at the same time. The same session will be also recorded and access will be provided to revise, recap or watch a missed session.
Whom Should I Contact If I Want to Know More Information About The Training?
- You can reach out to us by visiting our website and interact with our live chat support team. Our customer service representatives will assist you with all your queries. You can also send us an email at enquiry@excelr.com with your query and our Subject Matter Experts / Sales Team will clarify your queries or call us on 1800-212-2121 (Toll-Free number – India), +1(281) 971-3065 (USA), 800 800 9706 (India), 203-514-6638 (United Kingdom), 128-520-3240 (Australia).
What If I Miss A Live Session?
- Not a problem even if you miss a live Data Science session for some reason. Every session will be recorded and access will be given to all the videos on ExcelR’s state-of-the-art Learning Management System (LMS). You can watch the recorded Data Science sessions at your own pace and convenience.
Will I Get A Data Science Course Completion Certification From ExcelR?
- Yes, after successfully completing the course you will be awarded a course completion certificate from ExcelR.
What Are The Different Modes Of Payment Available?
- The different payment methods accepted by us are
- Cash
- Net Banking
- Cheque
- Debit Card
- Credit Card
- PayPal
- Visa
- Mastercard
- American Express
- Discover
Global Presence
ExcelR is a training and consulting firm with its global headquarters in Houston, Texas, USA. Alongside to catering to the tailored needs of students, professionals, corporates and educational institutions across multiple locations, ExcelR opened its offices in multiple strategic locations such as Australia, Malaysia for the ASEAN market, Canada, UK, Romania taking into account the Eastern Europe and South Africa. In addition to these offices, ExcelR believes in building and nurturing future entrepreneurs through its Franchise verticals and hence has awarded in excess of 30 franchises across the globe. This ensures that our quality education and related services reach out to all corners of the world. Furthermore, this resonates with our global strategy of catering to the needs of bridging the gap between the industry and academia globally.
