- Call Us +1-281-971-3065




Blog
Popular Blog



Data Science


Project Management
Digital Marketing




Robotic Process Automation



Agile


Data Analytics

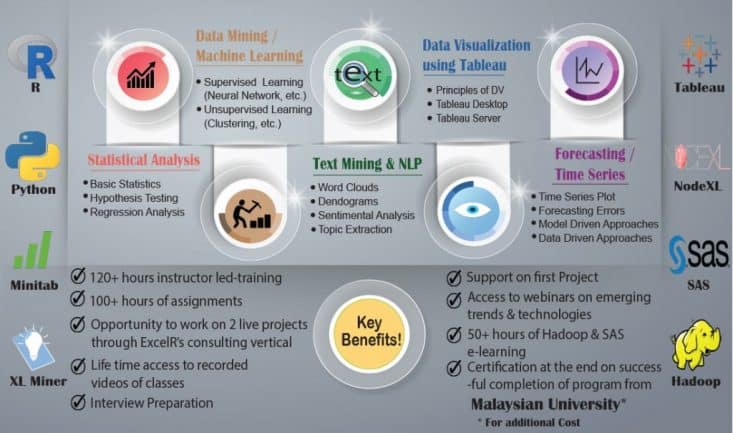
Business Analytics





