




“Language is a wonderful medium of communication”
We, as human beings can easily understand the meaning of a sentence within a fraction of a second. But machines fail to process such texts. They need the sentences to be broken down with numerical formats for easy understanding.

Introduction to Bag of Words
Bag of Words model is the technique of pre-processing the text by converting it into a number/vector format, which keeps a count of the total occurrences of most frequently used words in the document. This model is mainly visualized using a table, which contains the count of words corresponding to the word itself. In other words, it can be explained as a method to extract features from text documents and use these features for training machine learning algorithms. It tends to create a vocabulary of all the unique words occurring in the training set of the documents.
Want to Learn More About Machine Learning Concepts Click here
Applications Of Bag Of Words:
Bag of words is applied in the field of natural language processing, information retrieval from documents, and also document classifications.
It follows the following steps:

Learn more about Natural Language Processing
Real-Case Example:
We shall be taking a popular example to explain Bag-of-Words (BoW) and make this journey of understanding a better one. We all love doing online shopping, and yes, it is always important to look for reviews for a product before we commit to buying it. So, we will use this example here.
Here’s a sample of reviews about a particular cosmetic product:
- Review 1: This product is useful and fancy
- Review 2: This product is useful but not trending
- Review 3: This product is awesome and fancy
We can actually observe a 100 such contrasting reviews about the product as well as its features, and there is a lot of interesting insights we can draw from it, and finally predict which product is best for us to buy.
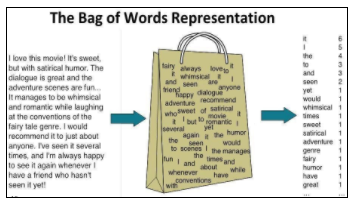
Now, the basic requirement is to process the text and convert it into vectorized form. And this can be easily done using Bag of Words which is the simplest form of text representation in numbers.
As the term says, this embedding represents each sentence as a string of numbers. We will first build a vocabulary from all the three above reviews which consist of these 10 words: ‘this’, ‘product’, ‘is’, ‘useful’, ‘and’, ‘fancy’, ‘but’, ‘not’, ‘trending’, ‘awesome’.
Before forming the table, we need to pre-process the reviews i.e., convert sentences into lower case, apply stemming and lemmatization, and remove stopwords.
Now, we can mark the word occurrence with 1s and 0s which is demonstrated below:
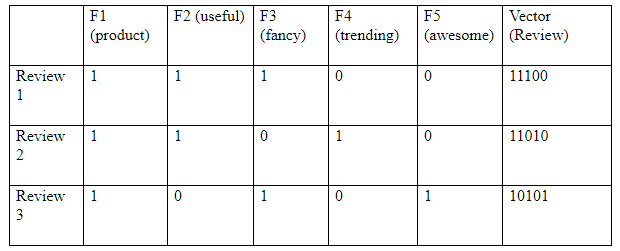
And that’s the core idea behind a Bag of Words (BoW) model where 1 denotes the presence of a word in the sentence review and 0 denotes its absence.
From the above explanation, we can very easily conclude that the BOW model only works when a known word occurs in a document or not, and so it does not consider the meaning, context, and order of the sentences. On the other side, it gives the insight that similar documents will have word counts similar to each other. Much precisely, more similar words in two documents will tend to be more similar in the documents.
Its Limitations:
But this word embedding technique has some pitfalls due to which developers prefer using TF-IDF or word2vec when dealing with a large amount of data.
Let’s discuss them:
- First issue arises in cases when the new sentences contain new words. If such happens, then the vocabulary size would increase and thereby, the length of the vectors would increase too.
- Additionally, the vectors would also contain many 0s, thereby resulting in a sparse matrix (which is what we would like to avoid)
- Secondly, we are gaining no information about the grammatical section nor are we focussing on the order of words in text.
Practical Implementation of bag of words using Python
Now, let’s have an experience of understanding a bag of words using the python programming language.
Step 1: Importing Libraries
Foremostly, we have to import the library NLTK which is the leading platform and helps to build python programs for working efficiently with human language data. Then, we need to put our text as the syntax shown below.


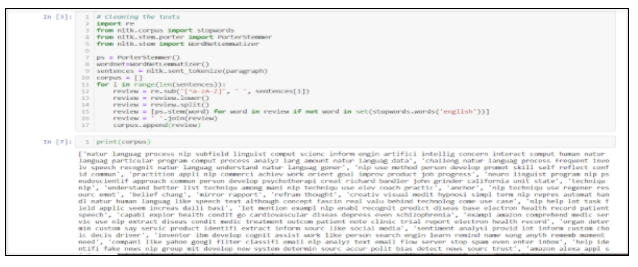
Step 2: Preprocessing the text
Those words which do not hold any significance to be used in our model implementation are known as Stopwords, and so it’s necessary to remove them. Removing punctuations, alphanumeric characters will also help in better result.

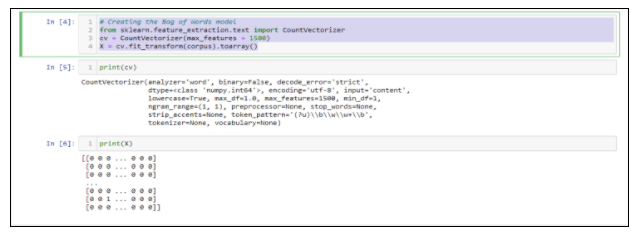
Step 3: BoW Model
It is not needed to code BOW whenever we need it. It is already available with many frameworks such as scikit-learn, CountVectorizer.














.svg)





